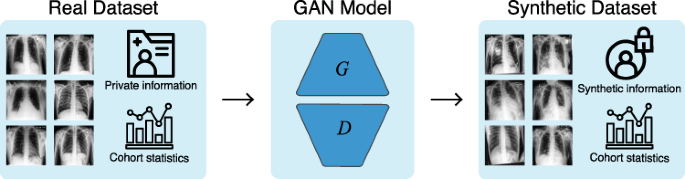
Background: Sharing sensitive data under strict privacy regulations remains a crucial challenge in advancing medical research [1]. Even with large-scale research collaborations to provide open-source datasets, most data is still isolated in hospitals and laboratories due to privacy concerns [2].
In medical research, information is often analysed at the level of cohorts rather than individuals. A potential solution to the medical data sharing bottleneck, is, therefore, the generation of synthetic patient data that, in aggregate, has similar statistical properties to those of a source dataset without revealing sensitive private information.
Among other deep learning approaches, Generative Adversarial Networks (GANs) [3] have demonstrated the capability to generate realistic, high-resolution imaging datasets [4]. GANs have been utilised within several medical domains, for example, to generate images of retinas [5], hematoxylin and eosin (H&E) stained breast cancer tissue [6], or brain MRIs [7].
Our contribution: Inspired by these domain-specific advancements we aim to establish a benchmark on synthetic medical imaging data generation. We analyse two different GAN models on two data modalities: Chest radiographs with 14 radiology findings and 2D brain computed tomography scans with 5 types of haemorrhages.
For each benchmark setting, we vary the composition of the real dataset by, for example, gradually increasing the number of included radiology findings (classes). We use the real datasets to train our GAN models, before generating equivalent synthetic data folds. To evaluate the data quality, we train predictive models on either the real or the synthetic datasets. By comparing the classification performance on a held-out, real data test fold, we can assess how realistic the generated images are. In our manuscript, we additionally compare the feature importance of the predictive models, analyse privacy considerations and conduct a large-scale reader study.
Our major findings: From Fig. 1a we can see that the relative performance for both GAN models increases when we decrease the number of radiology findings present in the chest x-ray dataset. The performance on synthetic data is approaching that of real data at a very low number of classes. This trend shows that GAN models and the generated data quality disproportionately benefit from a smaller label space, thereby confirming the significance of the class conditioning methods.

Two benchmarks: (a.) changing the number of classes and (b.) the number of samples per class for chest x-rays
At a low number of samples per class (Fig. 1b) we can also see a relative performance improvement for the synthetic data. However, this trend does not indicate a higher quality of synthetic data, but rather the growing effects of label overfitting during GAN training: Given a low number of samples, the variation within real images becomes too low, and the generative models resort to encoding the class information in unrealistic ways.

(c.) Synthetic brain CT scans and (d.) closest matching real nearest neighbours at a resolution of 256 x 256 pixels
In Fig. 2 we show some randomly sampled synthetic example images at a resolution of 256 x 256 pixels for the brain CT scans. There appears to be little noticeable difference in visual quality between the real and synthetic images, which is in agreement with a close-to-random classification accuracy of trained radiologists in the reader study. Below each synthetic image, you can see the most similar real image out of the entire training dataset. By comparing synthetics and nearest matching neighbours we can observe that the GAN model did not simply memorise training data, and is therefore likely to preserve private, potentially sensitive information.

(a.) Synthetic chest x-rays and (b.) closest matching real nearest neighbours at a resolution of 512 x 512 pixels
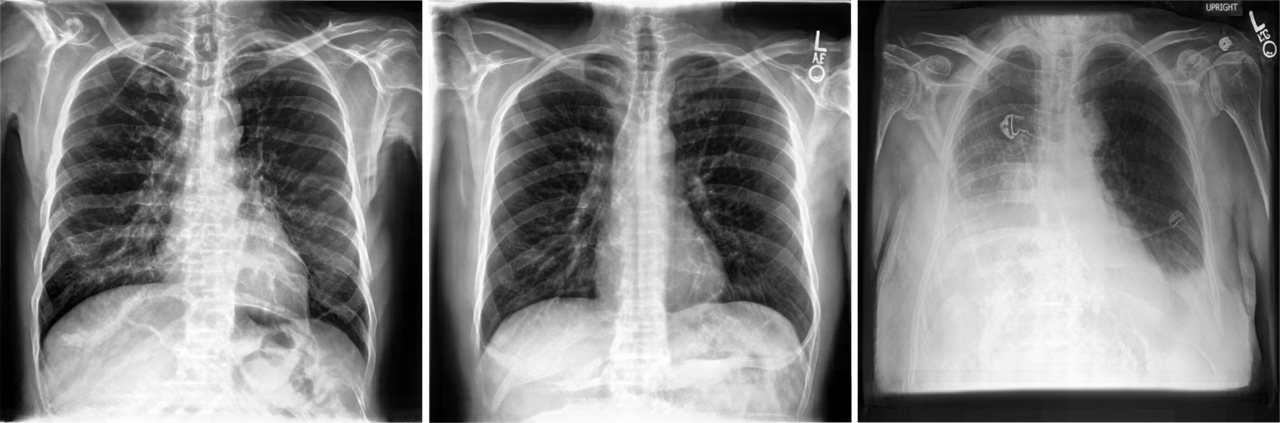
The quality of the chest x-rays in Fig. 3 also appears to be close to the quality of real data, without simply copying training images. However, for the support devices class, we observe visual artefacts in the synthetic x-rays. The GAN model fails to realistically generate tubes and other support devices, such as pacemakers or defibrillators, as shown in Fig. 4. These devices deviate strongly in their visual appearance when compared to the physiological chest outlining and were not accurately learned by the generative model. Crucially, our benchmark successfully captured the drops in visual quality due to the support devices class at higher resolutions.

(a.) Synthetic chest x-ray with artefact and (b.) closest real matching neighbour at a resolution of 512 x 512 pixels
Our key takeaways: Our results show that synthetic images generated by GAN models can closely mimic real images for different data modalities and for a range of dataset compositions. Importantly, our benchmark evaluation also captures regions in which the synthetic data quality drops significantly. With our in depth analysis we can offer valuable guidelines for future research.
Our benchmark analysis suggests that researchers should, in practice, choose datasets for GAN model development that have a manageable number of classes. Even though rare findings may be particularly interesting from a clinical perspective, they should be excluded from training when maximum performance is required. Moreover, our results indicate that GAN models might overfit on rare classes by encoding label information in unrealistic ways within the synthetic images. This can be very problematic as it could lead to predictions that are based on features not present in the real data distribution when trained on synthetics.
From a model perspective, the impact of the class conditioning mechanism on the predictive performance of derived classifiers suggests that research on the conditioning mechanism of GAN models may lead to further improvements in image quality.
For chest x-rays, our results indicate that at higher resolutions GAN models can still capture the data distribution of the physiological anatomic chest structure. However, our models fail to accurately capture the distribution of support devices that deviate strongly in their visual appearance. In practice, researcher need to carefully consider at what spatial resolution fine-scaled details emerge that differ significantly from other image parts.
While there remain open questions for further research, some of which we have discussed above, our results indicate that synthetic data sharing may in the future become an attractive and privacy-preserving alternative to sharing real patient-level data in the right settings.
References:
[1] Bernard Lo. Sharing Clinical Trial Data: Maximizing Benefits, Minimizing Risk. JAMA, 313(8):793–794, 2015.
[2] Sebastian Haas, Sven Wohlgemuth, Isao Echizen, Noboru Sonehara, and Günter Müller. Aspects of privacy for electronic health records. International Journal of Medical Informatics, 80(2):e26–e31, 2011.
[3] Ian Goodfellow et al. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, pages 2672–2680. Curran Associates, Inc., 2014.
[4] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In International Conference on Learning Representations, 2019.
[5] Pedro Costa et al. End-to-End Adversarial Retinal Image Synthesis. IEEE Transactions on Medical Imaging, 37(3):781–791, 2018.
[6] Adalberto Claudio Quiros, Roderick Murray-Smith, and Ke Yuan. Pathology GAN: Learning deep representations of cancer tissue. In Medical Imaging with Deep Learning, 2020.
[7] Changhee Han et al. Infinite Brain MR Images: PGGAN-Based Data Augmentation for Tumor Detection, pages 291–303. Springer Singapore, Singapore, 2020.



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in